November 23, 2025
The Financial Data Warehouse
You shouldn't build bots on free API tiers. How to avoid hitting rate limits by architecting a persistent data layer to feed data processing pipelines. Ingest once, serve forever. Localizing the market history.
This project sets the foundation for the main quest.
As I mentioned in the first post, the plan involves three interconnected projects:
- The Foundation: A data warehouse to ingest and store financial time-series.
- The Interface: A Next.js dashboard powered by AI agents that consume data from Project 1.
- The Model: A generative model to predict pricing dynamics (using the data from Project 1, of course).
So, Project 1 will be sticking around for a while. Even though I don't love the name, I couldn't come up with something cleverer yet, so we'll call it "The Financial Data API" for now. Eventually, it will just be the API.
Why build this?
Before defining exactly what The Data API is, let's look at the problem it solves with a hypothetical example.
Imagine you are a Data Analyst. You spend your days studying market data, producing visualizations, and trying to predict the future with machine learning. The tools you use already comprise a fair amount of complexity. On top of that, you have to deal with the "messy" outside world: data providers with strict rate limits, complex auth procedures, and different schemas.
Even if you handle that, you still have the hustle of keeping your local data up-to-date. You don't want to re-download the entire history of the S&P 500 every time you run a script (that burns your API credits and your patience). You just need the data from yesterday. And you need to make sure no days are skipped and no records are duplicated.
The purpose of this project is to solve these friction points in the most seamless way I can think of. The goal is simple: Ingest once, store forever, and serve instantly.
Architecture Overview
The system will be a single Python application, but clearly divided into layers that handle diverse logic. I like to think of it as a centralized "warehouse."
1. The Persistence Layer
At the center, we have a relational database. This is the source of truth where instruments and their price data live. It needs to be reliable, with clear specifications on what data is stored and how.
2. The Ingestion Layer
This layer handles the dirty work. It manages requests to external providers (like AlphaVantage) and adapts their responses to match the structure of our database. Crucially, it supports the "Adapter Pattern," so if we change providers in the future, the core logic stays the same.
3. The Interface Layer
This is the REST API that the rest of the world (and my future projects) will talk to. It serves data from the database and executes commands by request.
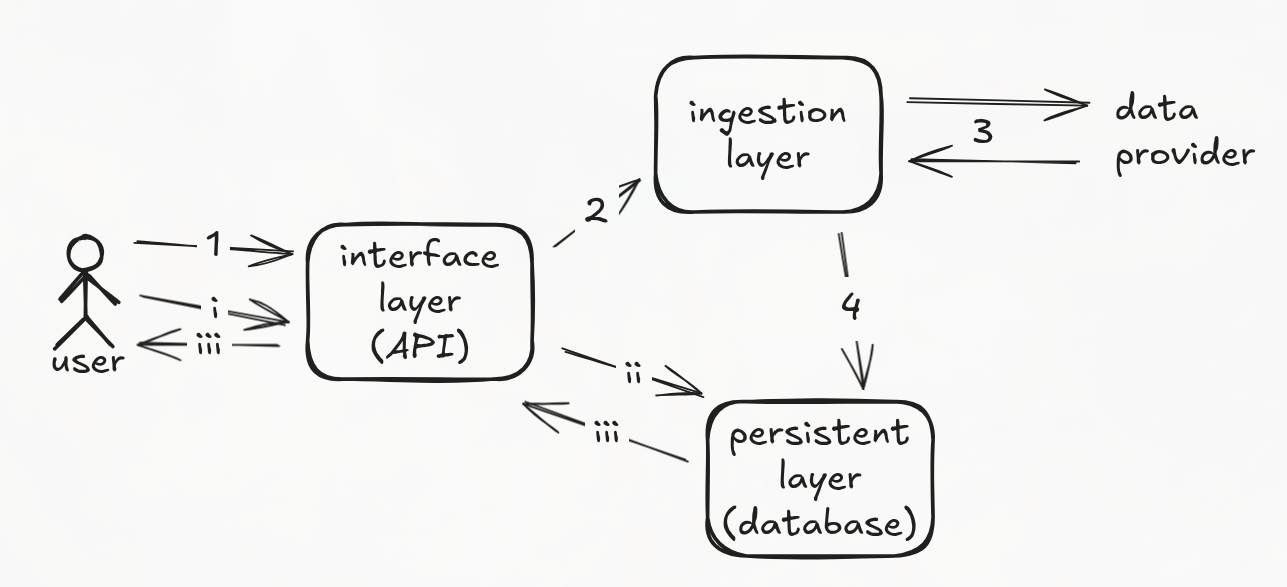
A Typical Workflow
Here is how these three components dance together:
- Onboarding: You hit the interface layer with a
POSTrequest to track a new instrument. - Ingestion: The API "wakes up" the ingestion layer. This worker sends a
GETrequest to the data provider, grabs the history, and adapts the response to our schema. - Storage: The clean data is saved into the persistence layer.
- Serving: Once the instrument is on-boarded, you can send a
GET /pricesrequest. This time, the API queries the database directly and serves the data instantly with no need to bother the external provider.
The Stack
The tools I selected for this architecture were chosen based on a weighted mix of job market popularity and my own familiarity.
Concretely, I am building this system using:
1. Python & Formatting
I stuck with Python (3.11) because it is the standard for data engineering. I also configured Black to format the code automatically. I prefer not to spend mental energy debating whether to put spaces around the equals sign; I just let the CI pipeline handle it.
2. The Data Source: Yahoo Finance
For the Ingestion Layer, I originally started with AlphaVantage. They have a decent free tier, but I ran into a major issue: the free endpoints don't provide adjusted close prices. This is a problem because, for example, if Apple splits 4-to-1, the raw price drops 75% overnight. If you feed that into a machine learning model, it thinks the market crashed. We need prices adjusted for splits and dividends.
Because of this, I swapped the provider to Yahoo Finance (via the yfinance library). It allows me to force auto_adjust=True, ensuring the historical data is actually usable for modeling, not just for display.
3. Database & Modeling: SQLModel
Here is where I tried something new. Instead of the classic SQLAlchemy (ORM) + Pydantic (Validation) setup, I used SQLModel.
It solves the "Double Declaration" problem. Usually, you define a User class for the database and a UserSchema for the API. With SQLModel, one class does both. It cuts the work in half, which I appreciate a lot.
4. The API: FastAPI
FastAPI has completely replaced Flask for me. It’s fast, async-native, and gets along perfectly with Pydantic.
Another great feature is that it automatically generates interactive OpenAPI documentation (/docs). I didn't write a single line of Swagger config, yet I have a fully testable UI for my API out of the box.
5. Testing: The "In-Memory" Trick
I didn't want to spin up a real Postgres database just to run unit tests as it is a very slow process that needs to run frequently. Instead, I set up pytest to swap the database engine with SQLite in-memory during tests.
- Technical Detail: I had to use a
StaticPoolso the data persists across different requests within the same test session. It makes the test suite run very fast.
6. Containerization
To avoid environment issues, I wrapped the API in a Docker container (using a lightweight python:3.11-slim image) and orchestrated the whole thing with Docker Compose. One command (docker compose up --build) sets up the API and the Postgres database, networked and ready to use.
7. CI/CD: The Guardrails
Finally, I set up a GitHub Actions workflow. Every time I push code, it:
- Checks out the repo.
- Installs dependencies.
- Checks formatting (Black).
- Runs the test suite. If I break something, I get a clear error before I can even think of merging.
Seeing it in Action
Enough theory. Let’s see what this actually looks like when you interact with it.
1. Onboarding a Ticker First, I tell the warehouse to start tracking NVIDIA.
POST /instruments/NVDA
Response:
The API fetches the history from Yahoo, cleans it, and stores it and returns a 200 successful response.
2. Asking for Data Now, I want the price action for the first week of 2024. Notice how the request is instantaneous because it's hitting my local DB, not Yahoo.
GET /prices/NVDA?from=2025-01-01&until=2025-01-05
Response:
[
{
"date": "2025-01-02",
"open": 135.96280522543205,
"high": 138.84202245285945,
"close": 138.2721710205078,
"instrument_id": 3,
"id": 23235,
"low": 134.5931847895647,
"volume": 198247200
},
{
"date": "2025-01-03",
"open": 139.9717090810043,
"high": 144.86037131104774,
"close": 144.4304962158203,
"instrument_id": 3,
"id": 23236,
"low": 139.69178686675932,
"volume": 229322500
}
]
3. The Smart Sync Let’s say a week passes. I don't want to re-download 20 years of history. I just hit the sync endpoint:
POST /prices/NVDA/sync
Response: The system checks the last date we have in the DB, asks Yahoo only for the days since then, and appends them.
{
"message": "Sync complete. 5 new records added."
}
What's Next?
This tool is now ready for my needs. It solves the data ingestion problem so I can focus on the fun stuff: The Dashboard and The Models.
While it currently relies on Yahoo Finance, the "Adapter Pattern" I used in the ingestion layer means I can swap in another provider (like Bloomberg or AlphaVantage) later without breaking the rest of the application.
But for now, the warehouse is open for business.
Next stop: Project 2 - The AI Financial Analyst. See you there.
(You can check out the full source code for this project on my GitHub.)